Managed Testing Explained
September 14, 2017
Q: How long does it take to schedule a test?
ALWAYS AVAILABLE 24/7: Self Serve Tests
SCHEDULING REDWOLF MANAGED TESTS: Immediately if resources available. Normal is two weeks. If test design / recon / etc… is necessary two to three weeks is recommended. Try to get on a calendar as soon as possible. Weekends are very popular and fill up quickly. Weekdays are less popular.
Q: How are permissions granted for testing?
RedWolf has a simple template you can send your provider to get permissions. To date we have not been denied testing by any vendor.
Note: Some vendors can give permission in hours. Most grant permission in under a week but some take up to 14 days. A few vendors, for specific offerings (mainly DNS) may require more time.
RedWolf has years experience with most cloud protection vendors and knows their testing authorization processes and requirements. We can help you obtain permissions quickly by providing the specific level of information required by each vendor.
Q: What kind of targets and attack vectors should I try?
What you should try first depends on your network environment and the kinds of assets you are protecting. We recommend going through an exercise to map your environment and identify your targets.
RedWolf offers customers a spreadsheet based test scoping template. Using this template will help narrow down the kinds of vectors that can be run. Remember that RedWolf has over 300 attack vectors as well as ‘kung-fu’ on how they are deployed vs. defense systems. The possibilities can be overwhelming so to help we’ve grouped the attack vectors & strategies into escalating levels of complexity as follows:

In a perfect world, the best way (i.e. the highest value outcome) involves running three tests, each with different focus:In a perfect world, the best way (i.e. the highest value outcome) involves running three tests, each with different focus:
Test 1: Baselining
• Determines the 50% and 70% performance/CPU thresholds of the critical services.
• Recommend testing up to 10 targets. Recommend local DNS, HTTP and HTTPS services,
• This is not an ‘attack’ but a ‘load test’. It identifies key performance thresholds that can be back-propagated to defense systems.
• If you do not know what throughput your services can give, how can you protect them?
• This should be run:
• At least once per year on all critical Internet facing services
• After every significant network change (to ensure that controls have been re-established properly)
• For each new deployment of an Internet-facing service
Test 2: Local Mitigation
• Tests local infrastructure, attack mitigation, load-balancers, and services under controlled attack conditions.
• Targets that should be included include the previous targets as well as VPN’s, communications services (e.g. Mail (SMTP & Web Mail access), and conferencing (e.g. Skype for Business)).
• Test first with 80% “Level 1 – Basic”, and 20% “Level 2 – Intermediate attack vectors”. Only after these are all ranked ‘Good’ or better should “Level 3 – Advanced” attack vectors be considered.
• Most vectors ramp-up carefully and slowly to identify any vulnerabilities before defenses activate.
• RedWolf tests a number of aspects on the local environment:
• Impact to user experience during test
• Infrastructure performance: routers, firewalls, load balancers, DNS and Web servers, during ramp-up
• Attack detection speed and accuracy
• Performance & utilization monitoring systems
• Mitigation control effectiveness
• Leakage & corresponding impact
• False positive detection
• Operational awareness / root-cause identification & control over systems
• This should be run as follows:
• Every year: repeating previous year’s weakest tests, adding in new targets and increasing the attack sophistication.
• followed by re-tests to ensure that any deficiencies have been addressed and that test coverage has been given to all critical targets
Test 3: 3rd Party / ISP / Cloud Mitigation
• Trusting a 3rd party with the fate of your organization shouldn’t be based on ‘blind-faith’, it should be ‘demonstrated capability’.
• RedWolf tests a number of aspects of cloud DDoS mitigation services:
• Impact to user experience during test
• Activation procedure (if not always-on)
• Specific cloud defense controls / mitigation approaches
• Quality of monitoring / alerts / notifications / communications / portal
• Speed of attack detection and mitigation
• Time to mitigate completely
• Leakage & corresponding impact
• False positive detection
• Adaptability to changing attack vectors
• Ideally this should be run with a 4-6 hour test window PER 3rd party defense system. In a 4 hour test window up to 8 different attack scenarios can be tested. This will include volumetric, connection-oriented, various Layer 7 attacks.
• This should be run:
• At least once a year for a ‘main-test’ of each 3rd party mitigator
• Followed by a re-tests to ensure that any deficiencies have been addressed and that test coverage has been given to all critical targets.
• Once for every new service protected by the 3rd party.
Q: Should I target a production or test environment?
If you are new to DDoS testing you may think it is better/safer to test a staging/test system vs. a production system. Based on RedWolf’s 12+ years of doing enterprise DDoS testing we have put together the following information to guide you to the choice that is right for you.
Fact 1: 95% of RedWolf customers test production systems.
When RedWolf started offering DDoS testing back in 2006 our teams though most organizations would be terrified of testing their production systems and would only test non-production staging systems. But we found out that even in 2006 about 25% of testing was to staging/test systems and 75% was to production systems. Over the years this has shifted and in 2016 only 5% of tests were against non-production systems. Only 3% were to staging/test and 2% were a production data center where production traffic had been diverted.
In terms of value obtained from testing, it is clear that it is always best to run a DDoS test in a production environment.
The reasons are:
1. Staging/testing environments differ significantly from production/staging environments: The configuration and firmware versions of upstream devices are almost never the same, and the number of servers behind load-balancers (and the performance/throughput licenses on devices) are vastly different.
2. The production environment is ultimately what is being defended. Logically it is better to know if a vulnerability exists in a production environment.
3. If a problem occurs in a production environment, it is as likely to be a Firewall, Load Balancer, WAF, or application server as it is a DDoS mitigation device. Testing with RedWolf is full-stack.
4. Operational monitoring of production systems more thoroughly than with test systems. During a test monitoring systems are as important as defense systems.
5. Test systems rarely perform well or the same way as production systems. There are just too many differences to production. It is often a waste of time to test a ‘staging’ system because so many differences mean the results don’t translate well to production.
6. If your DDoS mitigation system auto-learns traffic baselines (vs. having fixed activation thresholds) then those baselines will be vastly different in production vs. staging. If you want to test a staging environment with RedWolf make sure you use the RedWolf system to generate a baseline of legitimate traffic that resembles what you see in production. RedWolf can dedicate a pool ‘good traffic’ agents to interact with the site as real users do.
Q: At a high level, how is DDoS testing conducted?

1. SCOPING:Identifying what needs to be protected, what will be tested first, building a control matrix of alerting and defensive countermeasures and lines of responsibility. All 3rd party systems will be identified. This information is captured in a template spreadsheet called the ‘Test Plan Template’. As this sheet is filled out all details for the test will be contained in it. Copies of this spreadsheet can be distributed to participants.
2. DESIGN:Targets (domain names, URL’s, IP addresses) will be analyzed from an ‘attacker’ perspective and a profile will be created for each target. Potentially, this will uncover new potential attack variations that can be considered. Following the profiling a test plan will be created to fit within the given test windows. Each ‘test’ will take approximately 20 minutes with a 5 minute cool-down. The first few tests will be longer and later tests will be shorter. Approximately 2 tests can be run per hour. Creating the initial test plan will require some back/forth via secure email with your teams. The test plan is distributed in an XLS template that contains all the information for every party joining the test.
3. TEST IMPLEMENTATION: The tests will be created in the testing platform portal. These tests become part of your personalized test library and can be re-run in the future. You will have access to be able to inspect / review / clone / modify the tests.
4. PRE-TEST CHECKS: Every parameter for the test will be input and can be tested at very low levels (e.g. 1 request/sec) to ensure all the headers/cookies/randomization/etc… parameters are set properly.
5. TEST-WINDOW EXECUTION: Testing can be done 24/7. Two test staff will be on the bridge during test-day: one to manage the traffic / tests, and one to investigate, analyze and note outcomes/recommendations. A time-stamped log of these observations is included for every test vector and is extremely useful in reconstructing exactly what occurred during a test. During the test:
• OPS will take notes using platform portal.
• Traffic will only start when client agrees
• Client can stop traffic at any time
• Ramp-ups/down will only be done if agreed to by client
• Order of tests can be changed by request
• Monitors will show any outages / impact during test. Any such will also be announced on the bridge.
6. POST-TEST SELF-SERVE-ACCESS: Users can log in to the platform control portal, load any defined test or create new tests. This is excellent for post-test remediation and validating configuration changes before/after a more formal test. The platform provides 24/7 ability to log in and run tests yourself, at any level (big/small). There are always 10 ‘shared’ agents available and more can be added (virtually unlimited) by separate order/ticket. Training for 4 people is included.
Q: Can managed testing be scheduled 24/7?
Resources can be made available 7 days a week, 24/7.
Q: How many calendar days between each test session?
Services purchased must be used within 12 calendar months.
For managed testing: It is possible to schedule tests back-to-back and 24/7. Note: test windows need to be reserved ahead of time by at least 5 working days for resources to be guaranteed.
Q: What is included in a Managed report at the conclusion of testing?
Describe the contents of summary reports provided at the conclusion of testing.
A redacted report / template is available once a mutual non-disclosure agreement has been executed (MNDA). Reports are typically around 100 pages long and include executive summaries, individual test rankings, and detail sections for every attack vector with charts/graphs/observations.
A sample table of contents:

Q: How is the test monitored?
For managed testing exercises, prior to the actual test an all-hands meeting including OPS that will be invited to the test will cover:
1) The test plan
2) Testing methodology
3) Local requirements for OPS monitoring (e.g. who watches ISP’s routers, firewalls, load balancers, application servers) and what they need to record and how to record it.
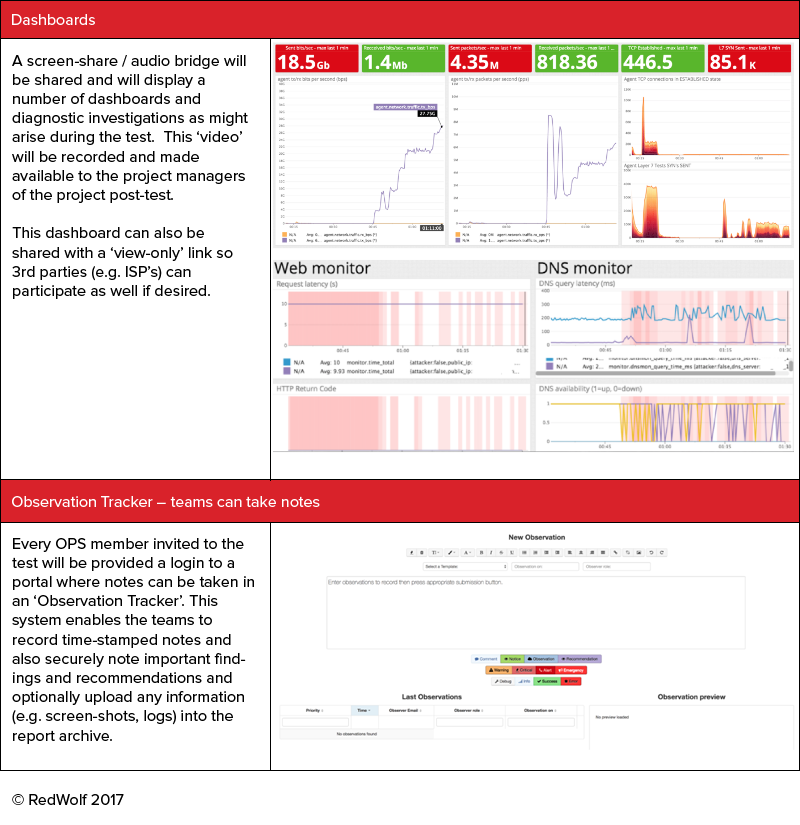
A series of dashboards are available for OPS to monitor. They will be made available 3 ways:
1) Via an audio/video screen-share during the exercise
2) Via the portal for OPS to log in during the test
3) Via a limited ‘read-only’ dashboard share link that is suitable for 3rd parties to receive
Also local OPS monitoring can be reported on in the tool via the ‘observation tracker’ on the portal. This is strongly recommended as all observations are time-stamped and can easily be correlated to the attack settings during the report/analysis phase.
Note that all targets will also be monitored from several ‘good agents’ in the Internet. The results of this monitoring information is also included on the dashboards.
Q: What consulting services do you provide in respect to DDoS preparedness? Please include which consulting is part or a normal engagement, or if additional consulting services are required.
Beyond basic Stress/Load DDoS testing RedWolf offers:
REDWOLF CONSULTATIVE OFFERINGS
Control Matrix Development
DDoS Testing / Control Validations
Functional Testing
Element Optimization / Configuration Review / Tuning
Run Book Development
Architectural Assessments
Architecting Resilient Cloud Security Deployments
Run-Book Development
Operations Training / Wargames
These services are billed out on a project basis.
Q: What mitigation providers have you worked with?
IN ALPHABETICAL ORDER:
Akamai (Prolexic)
Akamai CDN + Kona WAF
Arbor Cloud
BitGravity
CacheFly
ChinaCache
CloudFlare (CDN / WAF / DDoS)
DOSArrest
EdgeCast
F5 Silverline
Imperva / Incapsula (Cloud WAF / DDoS)
Level3
Neustar
NexusGuard
NSFocus
RadWare Cloud
Verisign
ZenEdge
Q: What on premise technologies have you worked with and what is your level of understanding?
The most common technologies RedWolf has good to great understanding of:
• Arbor Pravail / TMS
• RadWare Defense Pro / Alteon
• F5 LTM and ASM
• Citrix Netscalers
• Firewalls: Checkpoint, Juniper, Palo-Alto
• Routers: Cisco and Juniper
• SIEM: Arcsight, Splunk
• Most enterprise SNMP and NetFlow monitoring systems
• IPS: Sourcefire, McAfee
• Authentication: Entrust
• Web servers: Apache, IIS, Nginx, IBM, WebSphere
• (list goes on)
RedWolf prides itself on providing this type of testing for the largest enterprises in the world for over 12 years. As such our teams have gained tremendous exposure to virtually every enterprise infrastructure, defense, and monitoring system imaginable.
Our knowledge is not limited to:
DDoS Detection Systems
Cloud monitoring, flow-based, SNMP, SIEM log detection, Network Monitoring Systems
Cloud Computing
Optimal Auto-scaling, Leveraging Cloud CDN/DNS capabilities, Cloud infrastructure monitoring,
Linux kernel optimization
Cloud WAF
Rate Controls, Session Controls, rule-sets, cloaking back-end IP’s
Cloud DDoS Services
BGP (iBGP, eBGP, BGP Prepending, BGP Communities, GRE, Backbone Connectivity)
Monitoring / Alerting Strategies
ISP’s
Validating ISP throughput (BPS / PPS)
Validating route-attractiveness under attack conditions (where best-routed ISP gets all the traffic)
Issues with ISP mitigation and guidance to ISP mitigation policies and run-books.
DDoS Appliances
Threshold Tuning
Policy Configuration Guidance
Vendor expert introductions
Product Capabilities / Holes
HTTPS attack optimization
Challenge detection and evasion
Protecting API’s from DDoS (vs. regular browser users)
Advanced bypass techniques and vectors
Operationalization Issues with these technologies
Firewalls
Best-practice state-management and expiry
DDoS settings for Juniper, Cisco, Checkpoint and others
Protecting firewalls from being a bottleneck
Load Balancers
Best-practice configuration for F5, and Citrix devices for slow attacks
Optimizing TCP session expiry
Crypto-specific SSL DDoS and protection
Non-DDoS use-cases of these technologies (e.g. data scraping)
IPS
Getting the most from IPS systems without causing problems for upstream / downstream devices.
Minimizing false-positives
Servers
Authentication/authorization Systems (Entrust most popular)
Apache, IIS, NGINX, Java-based server issues and optimizations
Garbage collection problems while under DDoS attack
Mainframe
Protecting MQ applications tied to Internet infrastructure